
Temporally coherent person matting trained on fake-motion dataset
I. Molodetskikh, M. Erofeev, A. Moskalenko, and D. Vatolin
Contact us:
Abstract
We propose a novel neural network based method to perform matting of videos depicting people that does not require additional user input such as trimaps. Our architecture achieves temporal stability of the resulting alpha mattes by using motion estimation based smoothing of image-segmentation algorithm outputs, combined with convolutional-LSTM modules on U-Net skip connections. We also propose a fake-motion algorithm that generates training clips for the video-matting network given photos with ground truth alpha mattes and background videos. We apply random motion to photos and their mattes to simulate movement one would find in real videos and composite the result with the background clips. It lets us train a deep neural network operating on videos in an absence of a large annotated video dataset and provides ground truth training clip foreground optical flow for use in loss functions.
Key Features
- A novel fake-motion algorithm for generating neural-network training video clips from a dataset of images with ground truth alpha mattes and background videos
- A U-Net based deep neural network method with LSTM blocks and an attention module on skip connections
- A motion estimation based method for improving the output’s temporal stability
- Better than 8 different matting methods according to subjective evaluation powered by Subjectify.us
Architecture of the proposed neural network
The figure below demonstrates the architecture.
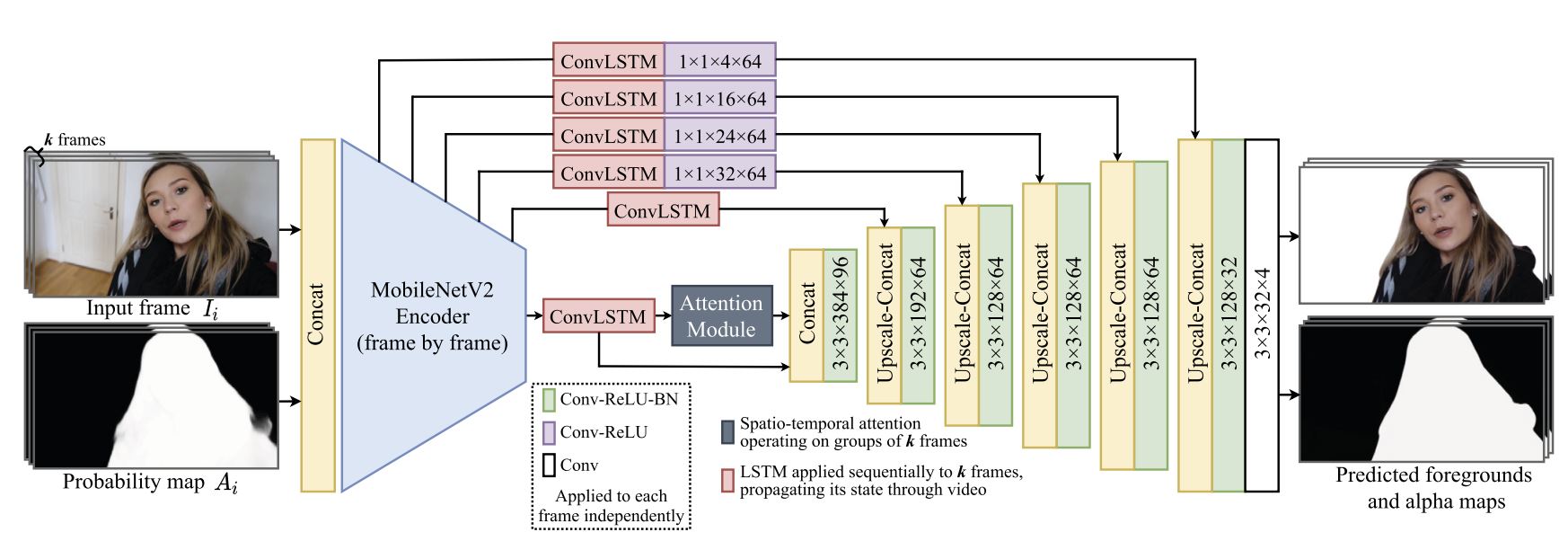 Some additional details:
Some additional details:
- The outputs of the 2nd, 4th, 7th, 14th, and 18th encoder’s blocks of the TorchVision implementation are used for skip connections
- To generate the probability map we used a pretrained DeepLabv3+ image-segmentation network from TorchVision
Dataset
We developed a novel fake-motion algorithm to generate training video clips from image foregrounds and video backgrounds by distorting the foreground image throughout the clip. The fake-motion procedure generates random optical-flow maps at three scales and uses them to warp the input foreground image and alpha mask to produce the foreground clip with the desired frame count.

To improve network resilience when a person partially leaves the video frame, we added to the optical flow a component that over the clip’s duration shifts the person halfway out of a frame and back, with a probability of \(\frac{1}{3}\).
Comparison
We conducted the subjective evaluation using Subjectify.us. In total more than 32,000 pairwise selections were collected and used to fit a Bradley-Terry model.
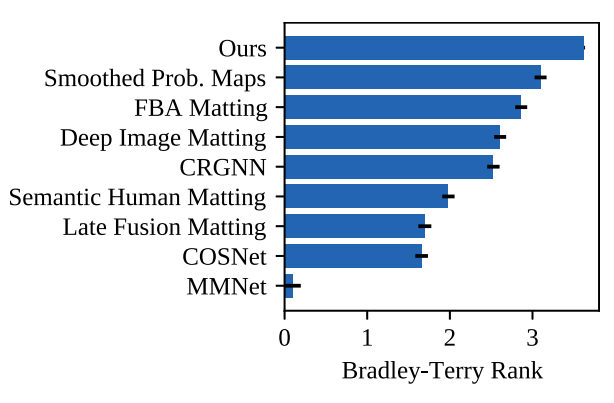
Below you can see objective evaluation results on clips from VideoMatting benchmark. The best result is shown in bold, the second-best is underlined and the third-best is shown in italics.
| Method | SSDA | dtSSD | MESSDdt | SSDA | dtSSD | MESSDdt |
|---|---|---|---|---|---|---|
| city | snow | |||||
| Ours | 69.651 | 15.314 | 0.695 | 56.338 | 30.240 | 0.662 |
| Smoothed Prob. Maps | 91.577 | 17.609 | 1.291 | 65.772 | 35.133 | 1.264 |
| FBA Matting | 57.700 | 30.825 | 1.613 | 27.113 | 20.881 | 0.423 |
| Deep Image Matting | 97.506 | 47.107 | 3.258 | 59.648 | 41.463 | 2.128 |
| CRGNN | 76.456 | 35.591 | 2.354 | 34.735 | 27.183 | 1.244 |
| Sem. Human Matting | 108.393 | 53.086 | 5.696 | 71.844 | 43.689 | 2.595 |
| Late Fusion Matting | 44.766 | 31.621 | 4.152 | 24.602 | 19.484 | 0.341 |
| COSNet | 271.878 | 62.798 | 22.387 | 156.617 | 58.536 | 9.424 |
| MMNet | 154.656 | 62.439 | 13.580 | 347.065 | 143.696 | 58.429 |
The second table shows objective evaluation results on five VideoMatte240K test clips.
| Method | SSDA | dtSSD | MESSDdt |
|---|---|---|---|
| Ours | 84.710 | 46.792 | 2.080 |
| Smoothed Prob. Maps | 117.253 | 53.836 | 4.452 |
| FBA Matting | 62.679 | 40.996 | 2.901 |
| Deep Image Matting | 165.094 | 100.595 | 15.039 |
| CRGNN | 140.095 | 84.434 | 13.900 |
| Sem. Human Matting | 166.325 | 113.648 | 22.300 |
| Late Fusion Matting | 29.146 | 25.459 | 0.845 |
| COSNet | 226.256 | 74.765 | 17.506 |
| MMNet | 445.550 | 156.778 | 75.171 |
The third table shows objective evaluation results on 100 fake-motion clips.
| Method | SSDA | dtSSD | MESSDdt |
|---|---|---|---|
| Ours | 102.371 | 72.880 | 1.818 |
| Smoothed Prob. Maps | 113.019 | 79.253 | 3.955 |
| FBA Matting | 114.101 | 92.686 | 4.613 |
| Deep Image Matting | 128.205 | 113.675 | 7.693 |
| CRGNN | 121.416 | 95.899 | 7.015 |
| Sem. Human Matting | 186.980 | 145.235 | 9.685 |
| Late Fusion Matting | 454.597 | 222.736 | 69.992 |
| COSNet | 610.056 | 142.895 | 33.037 |
| MMNet | 222.333 | 124.414 | 15.006 |
We believe the discrepancy between the subjective and the objective evaluation results can be attributed to the existing objective metrics’ limited ability to distinguish temporal coherence.
Cite us
@article{MOLODETSKIKH2022103521,
title = {Temporally coherent person matting trained on fake-motion dataset},
journal = {Digital Signal Processing},
volume = {126},
pages = {103521},
year = {2022},
issn = {1051-2004},
doi = {https://doi.org/10.1016/j.dsp.2022.103521},
url = {https://www.sciencedirect.com/science/article/pii/S1051200422001385},
author = {Ivan Molodetskikh and Mikhail Erofeev and Andrey Moskalenko and Dmitry Vatolin},
keywords = {Video matting, Semantic person matting, Semantic segmentation, Data augmentation, Temporal smoothing, Deep learning},
abstract = {We propose a novel neural network based method to perform matting of videos depicting people that does not require additional user input such as trimaps. Our architecture achieves temporal stability of the resulting alpha mattes by using motion estimation based smoothing of image-segmentation algorithm outputs, combined with convolutional-LSTM modules on U-Net skip connections. We also propose a fake-motion algorithm that generates training clips for the video-matting network given photos with ground truth alpha mattes and background videos. We apply random motion to photos and their mattes to simulate movement one would find in real videos and composite the result with the background clips. It lets us train a deep neural network operating on videos in an absence of a large annotated video dataset and provides ground truth training clip foreground optical flow for use in loss functions.}
}Contact us
For questions and propositions, please contact us: ivan.molodetskikh@graphics.cs.msu.ru, video@compression.ru
See also
References
1) M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: inverted residuals and linear bottlenecks,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
2) X. Shi, Z. Chen, H. Wang, D.-Y. Yeung, W.-k. Wong, and W.-c. Woo, “Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting,” in Advances in Neural Information Processing Systems, vol. 28, Curran Associates, Inc., 2015, pp. 802–810.
3) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017, pp. 5998–6008.
4) L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018.
5) AISegment dataset, available: https://github.com/aisegmentcn/matting_human_datasets/tree/1829b5f722024d29b780993f06b45ea3f47ba777, 2019.
6) X. Shen, X. Tao, H. Gao, C. Zhou, and J. Jia, “Deep automatic portrait matting,” in European Conference on Computer Vision, Springer, 2016, pp. 92–107.
7) N. Xu, B. Price, S. Cohen, and T. Huang, “Deep image matting,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
8) M. Forte, F. Pitié, “F, B, alpha matting,” preprint, arXiv:2003.07711, 2020.
9) X. Lu, W. Wang, C. Ma, J. Shen, L. Shao, and F. Porikli, “See more, know more: unsupervised video object segmentation with co-attention siamese networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
10) S. Seo, S. Choi, M. Kersner, B. Shin, H. Yoon, H. Byun, and S. Ha, “Towards realtime automatic portrait matting on mobile devices,” preprint, arXiv:1904.03816, 2019.
11) Q. Chen, T. Ge, Y. Xu, Z. Zhang, X. Yang, and K. Gai, “Semantic human matting,” in Proceedings of the 26th ACM International Conference on Multimedia, 2018, pp. 618-626.
12) Y. Zhang, L. Gong, L. Fan, P. Ren, Q. Huang, H. Bao, and W. Xu, “A late fusion CNN for digital matting,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
13) T. Wang, S. Liu, Y. Tian, K. Li, and M.-H. Yang, “Video matting via consistency-regularized graph neural networks,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 4902–4911.
14) R.A. Bradley, and M.E. Terry, “Rank analysis of incomplete block designs: I. The method of paired comparisons,” in Biometrika 39 (3/4) (1952) 324–345.